
Many pervasive and multifactorial disorders of modern noncommunicable and noninfectious diseases, such as obesity, asthma, migraine, and autism, need to be better understood, defined, and explored. Recently, medical and public health researchers have begun to take advantage of the huge increase in the amount of information available via the Internet and the concomitant advance in data science technology to explore potential disease-related factors and the temporal and spatial relationships among them at a variety of population levels.
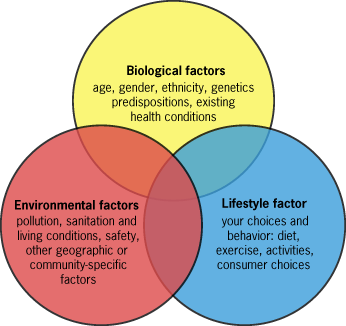
An individual's disease or health status can be thought of as a complex balance of a variety of biological, environmental, and lifestyle factors (Fig. 1). Quantifying these factors for large numbers of individuals can elucidate meaningful trends and aid in hypothesis generation. Historically, our knowledge of lifestyle and environmental factors and their interactions has been limited. To overcome this obstacle, epidemiology researchers are now using new methods to collect disease-factor information from publically available big data web-based or social-media-based streams. The data streams of social media contain gigantic volumes of mentions relating to symptoms, treatments, activities, events, consumer products use, and other related human behaviors. Surveillance of social media through search-term analysis can identify meaningful geographic and temporal patterns in these mentions, and that information can be compared with other available public data, such as census, public health, housing, weather, and environmental data, to better understand, quantify, and visualize the causes and origins of diseases.
Search volume analysis
Search volume analysis involves a quantitative investigation of the aggregate search-term volume from a variety of search engines such as Google or Yahoo, using publically available tools such as Google TrendsTM. These approaches provide temporal and spatial information about what people are searching for, and hypothetically, what they are doing, eating, or buying. This approach can be fine-tuned to validate the assumption that there is a correlation between human activities or behaviors and information-seeking patterns by comparing them to global, national, or local epidemiological statistics. It provides a rational starting point for identifying the optimal seasons and locations in which to administer informative surveys. The search volume approach does not assist in directly identifying demographic information, but it can be combined with census data to glean or infer the demographics of populations in different places.
The key step in search volume analysis is the development of appropriate search terms for a given research question (for example, a set of disease symptoms). Text analysis (for example, the generation of wordclouds that represent the frequency with which words are used in social media), set-generation methods (such as Google SetsTM), and crowdsourcing approaches (such as Amazon Mechanical Turk) can be useful in developing meaningful sets of search terms.
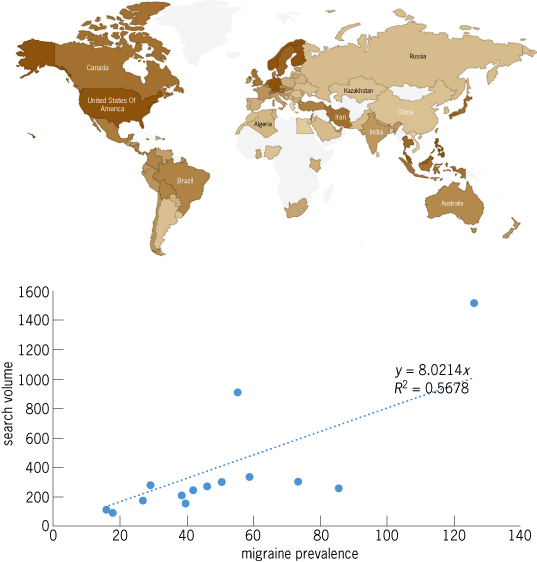
Google Trends analyses have recently been used to examine the temporal properties of Lyme disease outbreaks. Another simple example of a disease-related search volume analysis is shown in Fig. 2. We performed a Google Trends analysis of the term “migraine” in 40 different languages. The global, geographically specific relative search volume results were compared against migraine prevalence for 14 different global regions as reported by the World Health Organization (WHO). Despite the simplicity of the search term, a significant correlation could be seen. This example could be refined to target specific countries or symptoms, or to correlate these results to other global data (such as weather).
We have also recently applied search volume analysis to elucidate trends in consumer product use, which could be useful in the risk assessment of chemicals. Preliminary studies determined that there is a high degree of correlation between the Google Trend search volumes associated with a set of terms describing different types of cleaning products or personal care products and the numbers of those products actually found in homes in prior field studies. This finding will allow us to extrapolate our methods to predict product use for product categories for which we have little or no data.
Mining of social media (microblogging) streams
Another approach to exploring symptoms and related factors is to deal directly with massive amounts of microblogging data such as from Twitter or Tumblr. These microblogging environments can provide information similar to that of the search volume approach. The effort requires the development of natural language processing (NLP) methods, such as a named-entity recognition (NER) term tokenizer that identifies the key taxonomy for a given domain of interest. Appropriate taxonomies are required to more accurately identify and capture the representation of terms related to a specific symptom, disease, human activity, or behavior. An advantage of these methods over search volume analysis is that they can provide immediate correlations between symptoms and activities by tracking the use of the search terms by individuals. Geographic information can be collected as well, because users can set their microblog entries (such as the tweets posted in Twitter) to be geocoded. In addition, it is easier to extract demographic information for individuals from these data through user-provided profiles or from information within the microblog streams themselves.
One useful method we are developing is the mapping of microblog entries to the generalized activity and location codes described in the U.S. Environmental Protection Agency's (EPA) Consolidated Human Activity Database (CHAD), which the agency uses in assessments of exposure to air and chemical pollutants. It has previously been shown that NLP can be used to translate spoken word diaries directly into CHAD codes, and we are extending this to text-based diaries. This advance will allow us to map microblog entries directly to activities and locations relevant to pollutant exposures, and then to correlate them with disease symptoms or other relevant factors. To this end we have also begun taxonomy development related to CHAD activities in a simple nine-person “how would you tweet that?” experiment.
There have been numerous attempts to mix both search volume-derived data and microblogging data into the mainstream of predicting, extrapolating, and anticipating human behavior as it relates to disease and epidemic outbreaks, such as Google Flu Trends or Health Map. Those projects have found this method to be quite useful, which is why using this method to alleviate the big-data problem of elucidating the etiology of diseases seems plausible.
The look, listen, and learn paradigm
We have found a “Look, Listen, and Learn” paradigm that formalizes and combines the aforementioned methods (illustrated in Fig. 3) to be extremely useful in framing our approach to new questions. We can start from a global perspective, using aggregated data that contain temporal and spatial information related to specific keyword search terms, and then work our way down to the levels of populations, communities, and individuals, where we can collect detailed information from social-media data streams. This paradigm can be summarized as follows.
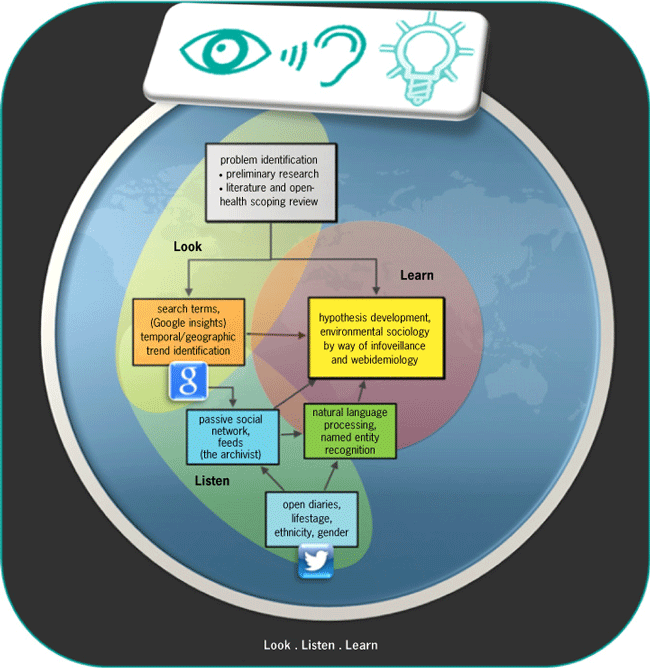
Look: problem identification and key-factor term development
The step starts by defining public-health problem targets (such as asthma, migraine, obesity, or psoriasis). An analysis of the medical literature (through PubMed) identifies keywords for search formulation (and also for inventory information that could potentially to be used later to validate the methods). In addition, open-health websites (such as CureTogether) can be explored for potential symptom- or treatment-related search terms. Text analyses or visualizations (such as word clouds) can be useful in extracting important terms from large volumes of abstracts or other text.
Listen: aggregate search-term volume analysis at different spatial, geographic, and temporal scales
This step involves using search-term volume analysis (by Google Trends, for example) at global (multilingual), population (monolingual), and community levels to elucidate potential temporal and geographical trends and identify target locations or populations of interest.
Learn: target populations and times of interest for detailed social media analysis leading to hypothesis generation
This step includes fine-tuning the analysis of any key identified locations and seasons through the NLP mining of geocoded social streams (microblogs), which have been appropriately anonymized. In this way, more detailed information can be explored, identifying hourly as opposed to seasonal patterns or demographic details gleaned from social media profiles, or other activities or factors.
Many of the factors explored in those three steps can be mapped against other available data to elucidate data gaps, visualize variations in disease prevalence over time or seasons, and explore correlations among potential factors. A selection of freely available spatial and temporal data and some useful tools are provided in Tables 1 and 2.
|
Data type |
Source |
URL |
|---|---|---|
|
Asthma statistics |
The global burden of asthma: executive summary of the Global Initiative for Asthma Program (GINA) Dissemination Committee Report |
http://onlinelibrary.wiley.com/doi/10.1111/j.1398-9995.2004.00526.x/full |
|
Pollen data |
American Academy of Allergy, Asthma & Immunology |
|
|
Air quality |
Air Now |
www.airnow.gov |
|
U.S. Census |
U.S. Census Bureau |
|
|
National Air Toxics Assessments |
U.S. Environmental Protection Agency (EPA) |
|
|
American Housing Survey (housing information) |
U.S. Census Bureau |
|
|
Diet and SES (Food Environment Atlas) |
U.S. Department of Agriculture Economic Research Service |
http://www.ers.usda.gov/data-products/food-environment-atlas/go-to-the-atlas.aspx#.UZ4keKLqnxA |
|
Weather forecast |
National Weather Service (National Oceanic and Atmospheric Administration) |
|
|
List of World Health Organization (WHO) regions and subregions |
WHO |
http://www.who.int/entity/healthinfo/statistics/ gbdestimatesregionallist.xls |
|
Migraine statistics |
WHO |
|
|
Fine particulate matter (PM2.5) map of Earth (served as comparison) |
National Aeronautics and Space Administration (NASA) |
http://www.nasa.gov/topics/earth/features/health-sapping.html |
|
Weather/activity relationship (served as comparison) |
NASA |
http://icp.giss.nasa.gov/education/urbanmaap/projects/ projects_asthma5.html |
|
Human activities (Consolidated Human Activity Database) |
U.S. EPA |
|
|
Human activities (American Time Use Survey) |
U.S. Department of Labor, Bureau of Labor Statistics |
|
Tool |
Definition of tool |
How tool was used |
URL |
Reference for definition |
|---|---|---|---|---|
|
Cure Together |
Free public site that allows people around the world to share quantitative information about their medical conditions, including symptoms and treatments that worked best for them |
Used to identify self-described symptoms and treatments |
||
|
Google Maps |
Map service viewed in web browser that provides geocodes |
Used to retrieve geocodes |
https://maps.google.com/ |
http://support.google.com/ maps/bin/answer.py?&hl= entopic=1687350&safe= on&answer=144352 |
|
Google Scholar |
Freely accessible web search engine that provides a simple way to broadly search for scholarly literature across many disciplines and sources |
Used to search for literature, in order to get an idea of factor and information landscape of disease in question |
||
|
Google Sets |
A tool within Google Drive that identifies keywords that are semantically related |
Used to generate symptoms that correspond with illness or disease |
https://drive.google.com |
|
|
Google Trends |
Public web facility by Google that shows how often a particular search term is entered relative to the total search volume across various regions of the world, and in various languages |
Used to identify trends geographically, using the keywords from Many Eyes, Google Scholar, and PubMed |
||
|
Many Eyes |
Free site from IBM that provides data visualization tools. Site allows users to upload datasets and produce graphic representations. |
Used to visualize relationships in abstracts and help formulate query or keywords |
||
|
Nice Translator |
Site that provides an improved interface for translating text on the Web |
Used to translate terms (symptoms) and identify other languages within a text |
||
|
Patients Like Me |
A health data-sharing platform |
Used to identify self-described symptoms and treatments |
||
|
PubMed |
Provides free access to the MEDLINE database, of indexed citations and abstracts to medical, nursing, dental, veterinary, health care, and preclinical science journal articles |
Used to search for literature, in order to get an idea of factor and information landscape of disease in question |
||
|
Tweet Archivist |
Twitter analytics tool used to search, archive, analyze, visualize, save, and export tweets based on a search term or hashtag |
Used to capture geocoded tweets |
This paradigm can be used for scoping analysis and hypothesis generation. Advantages and disadvantages of this approach are discussed in Table 3. Although these methods will never take the place of more traditional methods in epidemiology, they have the potential to inform the design of future focused studies that optimize the selection of geographic and seasonal sampling patterns, relevant cohorts, and studied factors.
|
Benefits [Pros (+)] |
Disadvantages [Cons (−)] |
|---|---|
|
Extremely useful and relevant tool for “real-time” screening of a wide-cast set of variables and undiscovered factors with minimum burden |
Not structured epidemiological queries |
|
Passive interrogation methods reduce Hawthorne effect and study participant biases common to traditional active survey methods |
“Web-savvy” demographics may vary from actual population demographics (age, gender, ethnicity, and socioeconomic status) |
|
Can be modified on the fly by language (that is, use nicetranslator.com), terms, rapidly regenerated, and is essentially “free” in terms of cost |
Social media monitoring by some (for example, government) may appear “big brother”...what are the ethical implications? |
|
This form of information modeling can give rise to understanding either data gaps, population variability, or technology penetration. |
Technology penetrance in certain populations may be an issue (some counties, states, and countries have fewer technology resources for a variety of reasons, including socioeconomic factors, government censorship, and so forth) |
[Disclaimer: The United States Environmental Protection Agency through its Office of Research and Development funded and managed the research described here. It has been subjected to Agency review and approved for publication. Mention of trade names or commercial products does not constitute endorsement or recommendation for use.]
See also: Environmental engineering; Epidemiology; Geographic information systems; Internet; Natural language processing; Public health; Risk assessment and management

