
Key Concepts
An acidic, chainlike biological macromolecule consisting of multiple repeated units of phosphoric acid, sugar, and purine and pyrimidine bases. Nucleic acids (Fig. 1) are collectively involved in the preservation, replication, and expression of hereditary information in every living cell. There are two types of nucleic acids—deoxyribonucleic acid (DNA) and ribonucleic acid (RNA). See also: Cell (biology); Deoxyribonucleic acid (DNA); Molecular biology; Purine; Pyrimidine; Ribonucleic acid (RNA)
Deoxyribonucleic acid
Each DNA strand is a long polymeric molecule consisting of many individual nucleotides linked end to end. The great size and complexity of DNAs are indicated by their molecular weights, which commonly range in the hundreds of millions. DNA is the chemical constituent of the genes of an organism; thus, it is the ultimate biochemical object of the study of genetics. Information is contained in the DNA in the form of the sequence of nucleotide building blocks in the nucleic acid chain. See also: Gene; Genetics
Nucleotides
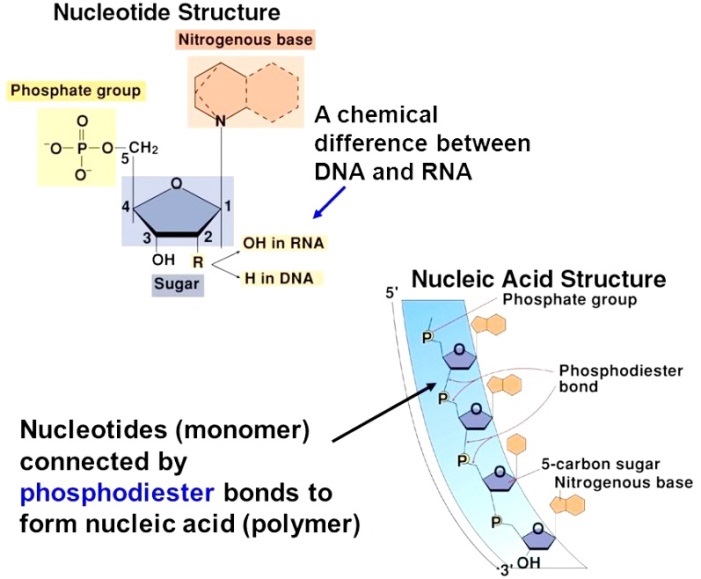
The number of nucleotide building blocks in DNA is relatively small—only four nucleotides constitute the vast majority of DNA polymeric units. These are deoxyadenylic, deoxyguanylic, deoxycytidylic, and deoxythymidylic acids. For purposes of brevity, these nucleotides are symbolized by the letters A, G, C, and T, respectively. Each of these nucleotides consists of three fundamental chemical groups: a phosphoric acid group, a deoxyribose 5-carbon sugar group, and a nitrogenous base that is a derivative of either a purine (adenine or guanine) or a pyrimidine (cytosine or thymine) [Fig. 2]. See also: Nucleotide
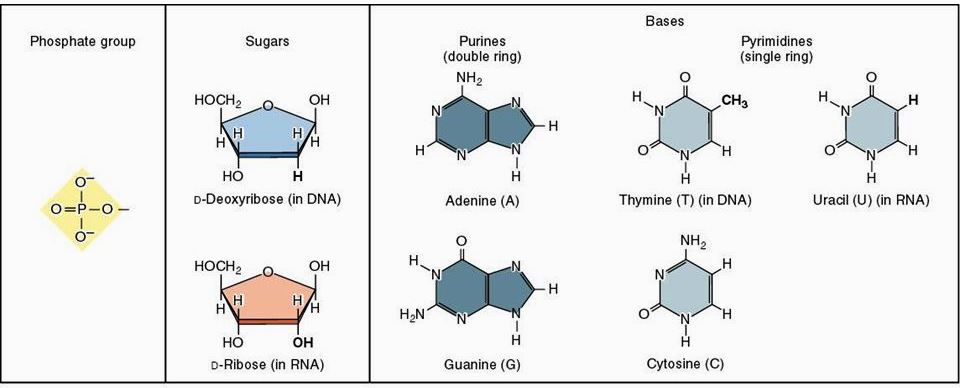
These are the only major bases found in most DNA; however, in specific sequences, certain methylated derivatives of these bases can be detected as well. In each nucleotide, the subunits are linked together in the following order: purine or pyrimidine base–ribose sugar–phosphoric acid. Removal of the phosphoric acid group leaves a base-sugar compound, which is called a nucleoside. The nucleosides and nucleotides are named for the base that they contain (see table).
| Base | Nucleoside | Nucleotide |
|---|---|---|
| Adenine | Adenosine | Adenylic acid |
| Guanine | Guanosine | Guanylic acid |
| Cytosine | Cytidine | Cytidylic acid |
| Thymine | Thymidine | Thymidylic acid |
| Uracil | Uridine | Uridylic acid |
It is necessary to denote the position of the phosphoric acid residue when describing nucleotides. Nucleotides synthesized by cells for use as building blocks in nucleic acids have phosphoric acid residues coupled to the 5′ position of the ribose sugar ring. Upon hydrolysis of DNA, however, nucleotides can be produced that have phosphoric acid coupled to the 3′ position of the sugar ring.
In intact DNA, the nucleotides are linked via phosphoryl groups that join the 3′ position of one sugar group to the 5′ position of the next sugar group. This 5′-to-3′ linkage of nucleotides imparts a polarity to each DNA strand, which is an important factor in the ability of DNA to form the three-dimensional structures necessary for its ability to replicate and to serve as a genetic template.
Helix
In 1953, James Watson and Francis Crick proposed a double-helical structure for DNA (Fig. 3) based largely on x-ray diffraction studies. It had been known previously that, in most DNAs, the ratios of A to T and of G to C are approximately 1:1. The Watson-Crick model attributes these ratios to the phenomenon of base pairing, in which each purine base on one strand of DNA is hydrogen-bonded to a complementary pyrimidine base in an opposing DNA strand.
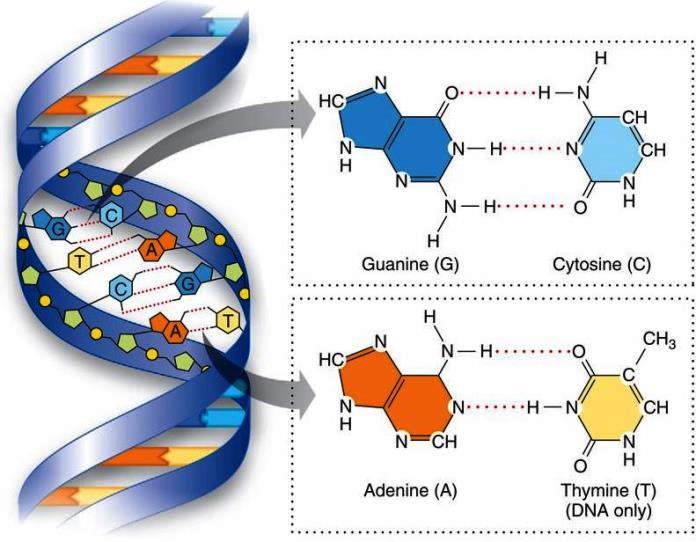
DNA can assume a structure called the B form, which is a right-handed helical configuration resembling a coiled spring. In most DNAs, there are two single DNA strands that compose each helix. The strands wind about each other, with their sugar-phosphate chains forming the coil of the helix and with their bases extending inward toward the axis of the helix. The configuration of the bases allows hydrogen bonding between opposing purines and pyrimidines. Each of the base pairs lies in a plane at approximately right angles to the helix axis, forming a stack with the two sugar-phosphate chains coiled around the outside of the stack. In the Watson-Crick model, the two opposing DNA strands have an opposite polarity; that is, they are antiparallel, with their 5′ ends lying at opposite ends of each double-stranded molecule. In addition, DNA can exist in helical structures other than the B form. One configuration, termed the Z form, is a left-handed helical structure. The Z form can exist in DNA sequences with alternating guanine and cytosine bases and may be functional in localized DNA regions; however, the B form is thought to predominate in most biological systems.
Sequences
The sequence of nucleotide pairs in the DNA determines all of the hereditary characteristics of any given organism. The DNA acts as a template that is copied, through the process of transcription, to make RNA. The RNA, in turn, serves as a template in a process by which its encoded information is translated to determine the amino acid sequences of proteins. Each amino acid in a protein chain is specified by a triplet of nucleotides (in RNA) or nucleotide pairs (in DNA) known as a codon. The set of correlations between the amino acids and their specifying codons is called the genetic code. Each gene that codes for a protein thus contains a sequence of triplet codons that corresponds to the sequence of amino acids in the polypeptide. This sequence of codons may be interrupted by intervening DNA sequences so that the entire coding sequence is not continuous. In addition to coding sequences, there also exist regulatory sequences, which include promoter and operator sequences involved in initiating gene transcription and terminator sequences involved in stopping transcription. Regulatory sequences are not necessarily made up of triplets, as are the codons. In order to study the regulation of a given gene, it is necessary to determine its nucleotide sequence. See also: Amino acid; Genetic code; Protein; Transcription
Function
In every living cell, as well as in certain viruses and subcellular organelles, the function of DNA is similar; that is, it encodes genetic information and replicates to pass this information to subsequent generations. The nucleotide sequence of DNA in each organism determines the nature and number of proteins to be synthesized, as well as the organization of the protein-synthesizing apparatus. The entire process of gene expression, by which the flow of information proceeds from DNA to RNA to protein, remains one of the most fertile areas of molecular biological research.
Ribonucleic acid
RNAs are long polymeric chains of ribonucleotides joined end to end in a 5′-to-3′ linkage. The primary chemical difference between RNA and DNA is in the structure of the ribose sugar of the individual nucleotide building blocks. Specifically, RNA nucleotides possess a 2′-OH group, whereas DNA nucleotides do not. Another major chemical difference between RNA and DNA is the substitution of uridylic acid, which contains the base uracil (2,6-dioxypyrimidine) for thymidylic acid as one of the four nucleotide building blocks. Thus, incorporation of radioactive uridine can be used as a specific measure of RNA synthesis in cells, whereas incorporation of radioactive thymidine can be used as a measure of DNA synthesis. Further modifications of RNA structure exist, such as the attachment of various chemical groups (for example, isopentenyl and sulfhydryl groups) to purine and pyrimidine rings, methylation of the sugars, and folding and base pairing of sections of a single RNA strand to form regions of secondary structure. Unlike DNA, nearly all RNA in cells is single-stranded (except for regions of secondary structure) and does not consist of double-helical duplex molecules. Another distinguishing characteristic of RNA is its alkaline lability. In contrast, DNA is stable to alkali.
Classes
Cellular RNA consists of three major classes of molecules that are widely divergent in size and complexity—ribosomal RNA, messenger RNA, and transfer RNA.
Ribosomal RNA
The most abundant class of RNA in cells is ribosomal RNA (rRNA). This class comprises those molecular species that form part of the structure of ribosomes, which are components of the protein-synthesizing machinery in the cell cytoplasm. The predominant RNA molecules are of size 16S and 23S in bacteria (the S value denotes the sedimentation velocity of the RNA upon ultracentrifugation in water), and 18S and 28S in most mammalian cells. All of the ribosomal RNA species are relatively rich in G and C residues. See also: Ribosomes
Messenger RNA
Another prominent class of RNAs consists of the messenger RNA (mRNA) molecules and their synthetic precursors. Messenger RNAs are those species that code for proteins. They are transcribed from specific genes in the cell nucleus, and they carry the genetic information to the cytoplasm, where their sequences are translated to determine amino acid sequences during the process of protein synthesis. The messenger RNAs thus consist primarily of triplet codons. Most messenger RNAs are derived from longer precursor molecules that are the primary products of transcription and that are found in the nucleus. These precursors undergo several steps known as RNA processing, eventually resulting in production of cytoplasmic messenger molecules ready for translation. See also: Cell nucleus
Transfer RNA
The third major RNA class is transfer RNA (tRNA). Transfer RNAs are small RNA molecules that possess a relatively high proportion of modified and unusual bases, such as methylinosine or pseudouridine. Each transfer RNA molecule possesses an anticodon and an amino acid–binding site. The anticodon is a triplet complementary to the messenger RNA codon for a particular amino acid. A transfer RNA molecule bound to its particular amino acid is termed charged. The charged transfer RNAs participate in protein synthesis; through base pairing, they bind to each appropriate codon in a messenger RNA molecule and thus order the sequence of attached amino acids for polymerization.
Transcription
The process of RNA biosynthesis from a DNA template is called transcription. Transcription requires nucleoside 5′-triphosphates as precursors and is catalyzed by enzymes called RNA polymerases. Unlike DNA replication, RNA transcription is not semiconservative; that is, only one DNA strand (the "sense" strand) is transcribed for any given gene, and the resulting RNA transcript is dissociated from the parental DNA strand. As is true of DNA synthesis, RNA synthesis always proceeds in a 5′-to-3′ direction. Because RNA synthesis requires no primer, as does DNA synthesis, the first nucleotide in any primary transcript retains its 5′-triphosphate group. Therefore, an important test to determine whether any RNA molecule is a primary transcript is to see whether it possesses an intact 5′-triphosphate terminus. As in DNA replication, base pairing orders the sequence of nucleotides during transcription. In RNA synthesis, uridine (rather than thymidine) base-pairs with adenine.
Function
The primary biological role of RNA is to direct the process of protein synthesis. The three major RNA classes perform different specialized functions toward this end. The 18S and 28S ribosomal RNAs of eukaryotes are organized with proteins and other smaller RNAs into the 45S and 60S ribosomal subunits, respectively. The completed ribosome serves as a minifactory where all the components of protein synthesis are brought together during translation of the messenger RNA. The messenger RNA binds to the ribosome at a point near the initiation codon for protein synthesis. Through codon-anticodon base pairing between messenger and transfer RNA sequences, the transfer RNA molecules bearing amino acids are juxtaposed to allow formation of the first peptide bond between amino acids. Then, the ribosome moves along the messenger RNA strand as more amino acids are added to the peptide chain.
RNA of certain bacterial viruses serves a dual function. In certain bacteriophages (viruses that infect bacterial cells), the RNA serves as a message to direct synthesis of viral-coat proteins and of enzymes needed for viral replication. The RNA also serves as a template for viral replication. Viral RNA polymerases that copy RNA rather than DNA are made after infection. These enzymes first produce an intermediate replicative form of the viral RNA that consists of complementary RNA strands. One of these strands then serves as the sense strand for synthesis of multiple copies of the original viral RNA. See also: Bacteriophage; Enzyme; Virus
RNA also serves as the actively transmitted genomic agent of certain viruses that infect cells of higher organisms. For example, Rous sarcoma virus, which is an avian tumor virus, contains RNA as its nucleic acid component. In this case, the RNA is copied to make DNA by an enzyme called reverse transcriptase. The viral DNA is then incorporated into the host cell genome, where it codes for enzymes that are involved in altering normal cell processes. These enzymes, as well as the site at which the virus integrates, regulate the drastic transformation of cell functions, inducing cell division and the ultimate formation of a tumor. Transcription of the viral DNA results in replication of the original viral RNA. See also: Reverse transcriptase; Rous sarcoma; Tumor viruses

