Key Concepts
A polymeric compound made up of various monomeric units called amino acids joined by peptide linkages. Proteins are central to the processes of life. They are fundamental components of all biological systems, performing a wide variety of structural and functional roles. For example, proteins are primary constituents of numerous structures of the body, including hair, tendons, muscle (Fig. 1), skin, and cartilage. Several hormones (for example, insulin and growth hormone) are proteins. The substances responsible for oxygen and electron transport (hemoglobin and cytochromes, respectively) are conjugated proteins that contain a metalloporphyrin (a combination of a porphyrin and a metal) as the prosthetic group. Chromosomes are highly complex nucleoproteins, that is, proteins conjugated with nucleic acids. Viruses are also nucleoprotein in nature. See also: Biopolymer; Chromosome; Cytochrome; Hemoglobin; Hormone; Virus
Furthermore, protein enzymes are the catalysts of nearly all biochemical transformations. Pepsin and rennin are examples of digestive enzymes involved in the breaking down of food. Deoxyribonucleic acid (DNA) polymerases are enzymes that duplicate DNA for cell division, other enzymes are needed to repair damaged DNA, and gene expression is carried out by ribonucleic acid (RNA) polymerases. The chemical reactions used in metabolic pathways for carbohydrates (citric acid cycle or Krebs cycle), lipids, amino acids, and energy production (oxidative phosphorylation) are catalyzed by protein enzymes. All living things contain proteins because they serve as the molecular tools and machines of life. See also: Biochemistry; Deoxyribonucleic acid (DNA); Energy metabolism; Enzyme; Metabolism; Protein kinase; Ribonucleic acid (RNA)
Amino acids
Structurally, the amino acids that comprise proteins are joined together in a chain by peptide (amide) bonds between the α-carboxyl groups and the α-amino groups of adjacent amino acids. The first amino acid in a protein usually contains a free α-amino group, as shown below (R, R′, and R′′ are unique side chains). Proteins generally contain from 50 to 1000 amino acids per chain. Small chains of up to 50 amino acids are usually referred to as peptides or polypeptides. See also: Amino acid; Peptide
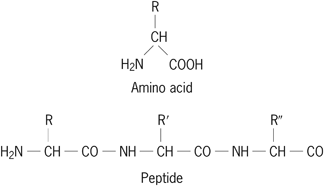
Of the more than 200 amino acids that have been discovered either in the free state or in small peptides, only 20 amino acids, or derivatives of these 20, are present in mammalian proteins. They are alanine, arginine, asparagine, aspartic acid, cysteine, glutamic acid, glutamine, glycine, histidine, isoleucine, leucine, lysine, methionine, phenylalanine, proline, serine, threonine, tryptophan, tyrosine, and valine. In general, the amino acids can be grouped according to similarities in size, shape, charge, aromaticity, and polarity. Each has a unique side chain (represented by R, R′, and R″ in the peptide structure shown above) that defines the chemical properties of the amino acid. Except for glycine, amino acids have an inherent asymmetry referred to as chirality. In all natural proteins, they are of the l-configuration. Amino acids with the mirror-image configuration are d-amino acids. Both d- and l-amino acids occur in the free state and in small peptides. In addition, commonly occurring derivatives of these 20 amino acids are cystine, hydroxyproline, and hydroxylysine. Cystine results from the oxidation of two cysteines to form a disulfide bridge. Hydroxyproline and hydroxylysine are formed by the enzymatic hydroxylation of proline and lysine, respectively.
Biosynthesis
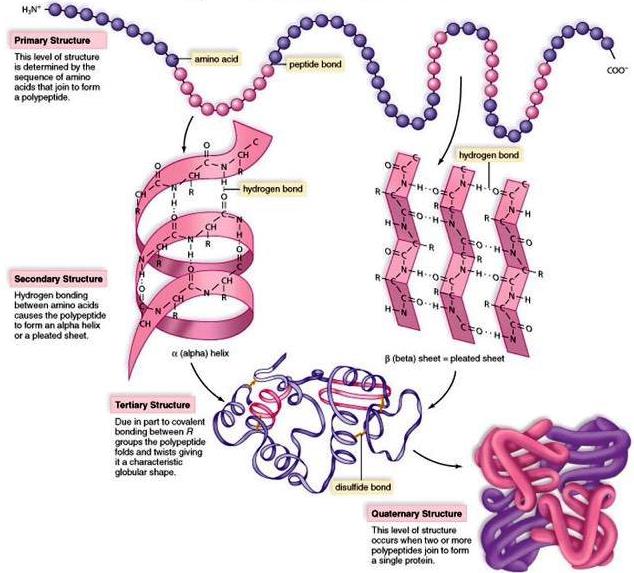
The linear arrangement of amino acids in a protein is termed its sequence (primary structure) [Fig. 2]. The sequence is highly specific and characteristic for each particular protein. It is determined by the DNA sequence of each protein's gene that is expressed in the form of messenger RNA (mRNA). Elucidation of the mechanism by which proteins are built up from free amino acids has been one of the key problems of molecular biology. See also: Gene; Molecular biology
Although a few proteins (for example, collagen) are stable indefinitely in adulthood, most body proteins are in a continual process of turnover, involving degradation and synthesis. For example, the half-life of serum proteins in humans is about 10 days. Each amino acid is activated by adenosine triphosphate (ATP) by a specific enzyme called an aminoacyl-tRNA synthetase. The synthetase enzymes establish the relationship between specific nucleotides and amino acids, forming the basis for the genetic code. The activated amino acid is covalently attached to a transfer RNA (tRNA) that contains a triplet of nucleotides (anticodon) at one end. Each triplet of nucleotides is unique for one amino acid. Protein synthesis, the joining of amino acids to form polypeptides, takes place on the ribosome, which is a large ribonucleoprotein complex that translates mRNA into proteins. On the ribosome, aminoacyl-tRNA binds specifically to a segment on mRNA through bonding between the anticodon on the tRNA and a complementary codon of three nucleotides on the mRNA. Two activated aminoacyl-tRNA complexes bind adjacent mRNA codons and then react together to form a peptide bond. The process continues until the synthesis of the entire protein is complete. See also: Genetic code; Nucleotide; Protein degradation; Ribosome
Proteins of similar function from different species have a common genetic origin and thus have related sequences. When differences exist in the sequence, changes are usually conservative, such as the replacement of one small hydrophobic amino acid by a different small hydrophobic amino acid. The degree of similarity between one protein in two different animal species has been used often to evaluate the relative genetic distance of the two species. Nonconservative changes can alter the ability of a protein to function, as is evident by the single amino acid difference between normal and sickle human β-globin. Sickle β-globin contains valine at a position normally occupied by glutamic acid. This single amino acid change alters the overall structure of hemoglobin, which in turn alters the shape of the red blood cell. When a person inherits the gene for sickle β-globin from both parents, it results in the disease known as sickle cell anemia. See also: Proteins, evolution of; Sickle cell disease
Structure
Proteins are not stretched-out polymers; rather, each protein adopts a specific extended or compact and organized structure called its native structure (Fig. 2). It is still not completely understood how proteins “fold” into their structures, nor is it possible to accurately predict the complete structure from its amino acid sequence. In general, after synthesis on the ribosome, a polypeptide chain folds to its native structure. In order to prevent the misfolding of certain proteins, chaperone proteins intervene to facilitate proper folding. Proteins that become misfolded or that have lost their native structure pose a major problem in cells. Certain diseases, including cystic fibrosis and Alzheimer's disease, are characterized by misfolded proteins. In cystic fibrosis, a mutation in the chloride ion channel protein prevents the final stages of protein folding and leads to deficiencies in ion transport across cell membranes. In Alzheimer's disease, a protein known as amyloid precursor protein takes on a misfolded shape that causes the protein to clump together, ultimately forming plaques in the brain. See also: Alzheimer's disease; Cystic fibrosis; Molecular chaperone; Protein folding
The polypeptide backbone of a protein can fold in several ways by means of hydrogen bonds between the carbonyl oxygen and the amide nitrogen (Fig. 3). Structural elements created by backbone hydrogen-bonding interactions in the polypeptide are called secondary structures and include α-helices, β-sheets (pleated sheets), and turns (Fig. 2). In helices, the backbone is coiled in a regular fashion that brings peptide bonds separated by several amino acids into close spatial approximation. The stability of a helix is attributed to hydrogen bonds between these peptide bonds. In addition to α-helices, polypeptides form β-sheet structures that are made of two or more segments that run parallel or antiparallel to each other and connect through backbone hydrogen bonds. See also: Hydrogen bond
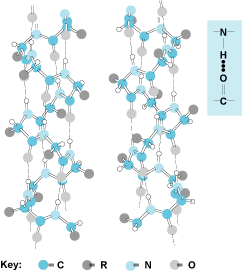
 NHCOC units form the backbone, which spirals up in a left-handed or right-handed fashion. (The right-handed configuration is adopted in natural proteins with l-amino acids.) Hydrogen bonds are indicated by the broken lines. Note that the side chains (R) are all directed out from the helix. There are 3.7 amino acids contained in one complete turn. The structure at the right (inset) shows the hydrogen bond. (Credit: J. T. Edsall and J. Wyman)
NHCOC units form the backbone, which spirals up in a left-handed or right-handed fashion. (The right-handed configuration is adopted in natural proteins with l-amino acids.) Hydrogen bonds are indicated by the broken lines. Note that the side chains (R) are all directed out from the helix. There are 3.7 amino acids contained in one complete turn. The structure at the right (inset) shows the hydrogen bond. (Credit: J. T. Edsall and J. Wyman)The third level of folding in a protein (tertiary structure) [Fig. 2] comes through interactions between different parts of the molecule. At this level of structure, various secondary structure elements are brought together and interact through many types of associations. Hydrogen bonds between different amino acids and peptide bonds, hydrophobic interactions between nonpolar side chains of amino acids, and salt bridges all contribute to the tertiary structure specific to a given protein. In addition, disulfide bridges formed between two cysteines at different linear locations in the molecule can stabilize parts of a three-dimensional structure by introducing a covalent bond as a cross-link. The result is a unique architecture that is predetermined by the particular sequence of amino acids in the protein.
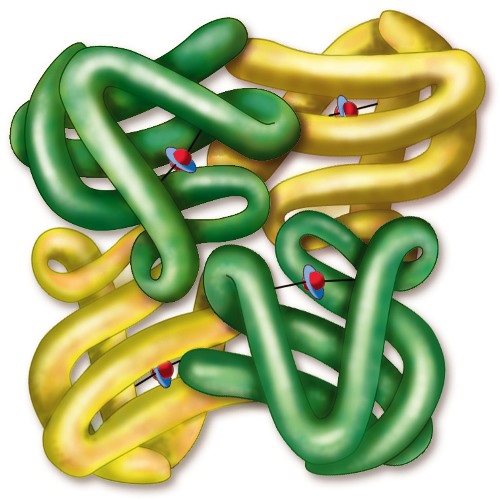
Finally, some proteins contain more than one polypeptide chain per molecule. This feature is referred to as the quaternary structure (Fig. 2). There is usually a high degree of interaction between each subunit, for example, between the α- and β-globin chains of hemoglobin. The tetrameric structure of hemoglobin exemplifies how four individual polypeptide chains (two α-chains and two β-chains) function cooperatively (Fig. 4). The binding of oxygen to one subunit causes a conformational change in the protein that facilitates the binding of oxygen to the other subunits. Thus, the cooperative binding of oxygen to hemoglobin is coordinated to facilitate oxygen binding in the lungs and its release in the tissues where oxygen pressure is slightly lower.